1) 모델을 코드로 ‘펼쳐’ 보기 (내부 구조 탐색)
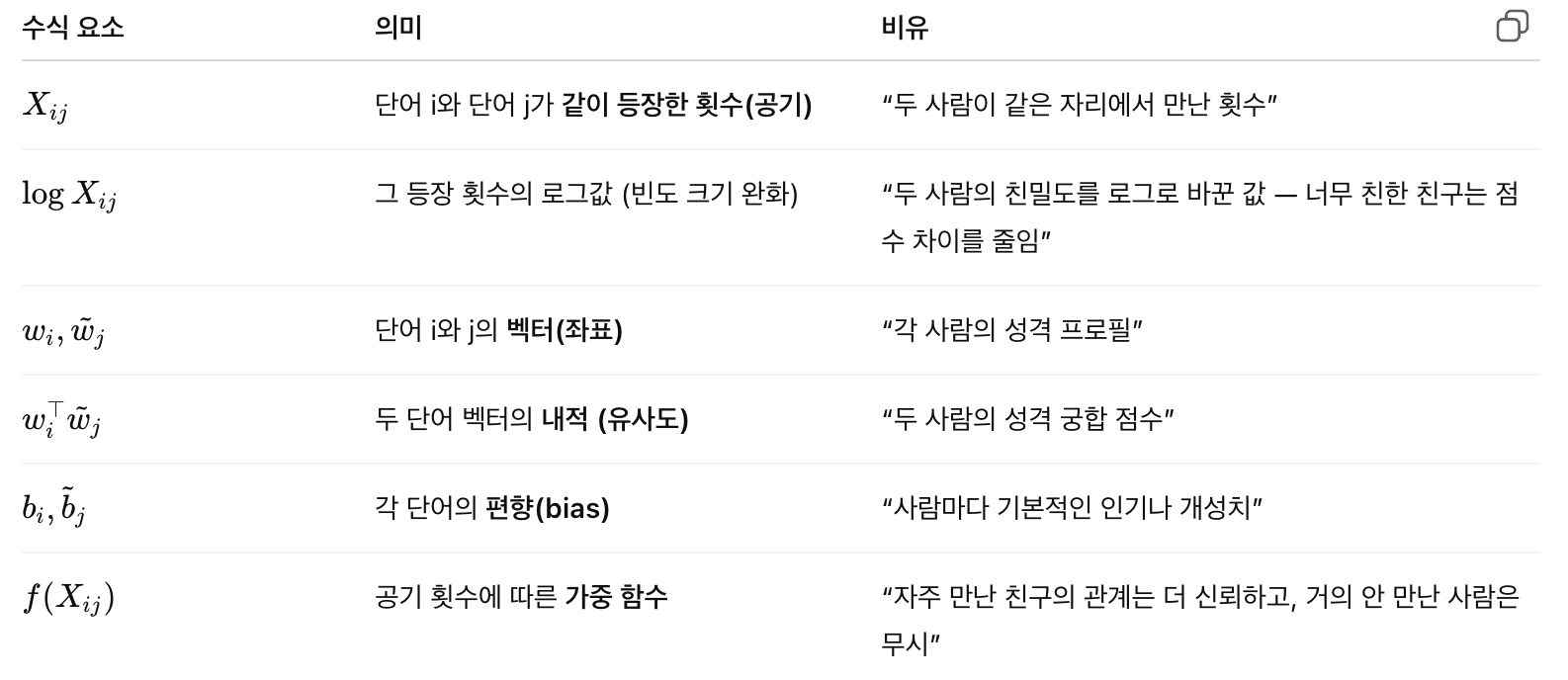
api.load("glove-wiki-gigaword-50")는 Gensim의 KeyedVectors 객체를 반환합니다.
이건 “단어 → 벡터” 해시맵과 벡터 행렬을 들고 있는 테이블이지, 신경망 그래프가 아닙니다.
import gensim.downloader as api
model = api.load("glove-wiki-gigaword-50") # KeyedVectors
# 기본 정보
type(model) # gensim.models.keyedvectors.KeyedVectors
len(model) # 어휘수 (vocab size)
model.vector_size # 50
# 어휘(단어 DB) 확인
list(model.key_to_index)[:10] # 사전에 들어있는 단어 10개 보기
"pizza" in model # True/False (존재 여부)
# 단어 벡터/유사도
vec = model["love"] # shape: (50,)
model.most_similar("king") # [(단어, 유사도), ...]
model.similarity("king","queen")
# 전체 임베딩 행렬 접근
model.vectors.shape # (vocab_size, 50)
# 인덱스→단어, 단어→인덱스
model.index_to_key[:5] # ["the","of","and", ...] (빈도 높은 순)
model.key_to_index["love"] # 정수 인덱스
2) 단어 DB(어휘집), OOV, 그리고 아키텍처
2-1. “없는 단어” = OOV(Out-Of-Vocabulary)
- GloVe/Word2Vec 같은 정적 임베딩은 학습 시점에 고정된 어휘집을 가집니다.
- if word in model이 False라면 그 단어는 사전에 없음(OOV) 이라는 뜻.
- 별도의 “DB”가 있다기보다, 모델 내부의 어휘 해시맵 + 벡터행렬이 곧 그 DB입니다.
OOV를 다루는 대표 전략
- 전처리 강화: 소문자화, 표제어/자연어 정규화, 구두점 제거 등으로 매칭률↑
- UNK 토큰: 없으면 평균/영벡터/무작위 초기화로 대체
- 서브워드 임베딩 사용: fastText는 문자 n-gram으로 OOV도 벡터 생성 가능
2-2. GloVe의 “아키텍처” (훈련 관점)
- GloVe는 신경망이 아니라, 공기(共起)행렬 기반의 행렬분해/회귀 모델에 가깝습니다.
- 대규모 말뭉치에서 단어-단어 공기횟수 XijX_{ij} 를 세고,
두 임베딩의 내적 + 편향이 logXij\log X_{ij}를 잘 근사하도록 가중 최소제곱 손실을 최적화합니다.
대략적인 목적식(아이디어만):

훈련이 끝나면 보통 wiw_i와 w~j\tilde{w}_j를 평균내거나 wiw_i만 사용해서 최종 단어 벡터로 씁니다.
다운스트림에서는 그냥 “단어→벡터 조회” 테이블만 쓰면 됩니다.
비교: Word2Vec(CBOW/Skip-gram)은 “주변 단어를 예측”하는 예측 모델(negative sampling) 이고,
GloVe는 “공기 통계의 로짓을 근사”하는 카운트 기반 모델이에요.
결과물은 둘 다 정적 단어 임베딩 테이블이라는 점은 같습니다.
🔹 GloVe의 핵심 수식
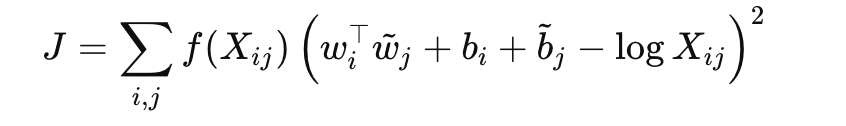
이제 이걸 비유로 바꿔서 하나씩 설명하자면:
🔸 비유로 풀어보면
GloVe는 이런 일을 하는 셈이에요 👇
“단어라는 사람들을 큰 파티에 전부 불러 모으고,
누가 누구랑 얼마나 자주 대화했는지를 기록한 뒤,
‘비슷한 친구들과 자주 어울리는 사람들끼리 가깝게 앉히자’는 식으로 자리 배치를 최적화하는 것.”
그래서 모델이 하는 일은 결국:
💬 “단어 쌍들의 친밀도(=log X_ij)를, 두 벡터의 거리(=내적 + 편향)로 잘 설명하도록
성격 좌표(w_i, w_j)를 조정하는 것.”
이 과정을 수학적으로 표현한 게 바로 위의 JJ입니다.
즉, “모든 단어쌍의 예상 친밀도와 실제 친밀도의 차이 제곱을 최소화”하는 거예요.
🧩 왜 이런 식이 의미 있는가?
- “man - woman ≈ king - queen” 같은 관계가 나타나는 이유는
이 벡터 공간이 단어 간의 **통계적 관계(log X_ij)**를 기하학적 거리로 보존하기 때문이에요.
즉, **공기 행렬(단어 동시출현 통계)**을
“언어의 의미 공간”이라는 좌표계로 압축 변환하는 과정이라고 생각하면 됩니다.
🔹 최종적으로 남는 건
훈련이 끝나면 wiw_i (혹은 평균된 벡터)를 남기고 나머지는 버려요.
이게 바로 model["love"] 같은 벡터예요.
그래서 “love”라는 단어를 꺼내면
love ≈ [0.2, -0.1, 0.7, ...]
이런 50차원 성격 프로필이 나오는 거죠.
💡 전체 비유 요약
GloVe는 언어 속 사람(단어)들을 거대한 파티장에 모아
“누가 누구랑 자주 어울리는지” 관찰하고,
그 관계를 가장 잘 설명하는 **좌석 배치(=벡터 좌표)**를 찾는 과정이에요.이렇게 얻은 좌표 공간에서는
의미가 비슷한 단어들이 가까이 앉아 있고,
**관계가 닮은 단어쌍(king-queen, man-woman)**은
방향이 비슷한 벡터로 나타나게 됩니다.
'AI' 카테고리의 다른 글
| Semantic Deduplication (의미 기반 중복 제거) (0) | 2025.10.28 |
|---|